做完了Kaggle上的第一个竞赛,也是多亏了一直在看别人分享的kernel和discussion,最后一天看到有人放出了代码和数据,才没有被赶出前10%,获得了一个铜牌。之前在GCP上一直自己在做的code在别人释放出来代码后也排不进,不过还是从中学到了很多东西,我想着写个总结来分享一下经验,并且提醒自己在以后的竞赛中要注意的事项。
各个步骤的重要程度
这点是我在CPMP大神发表在竞赛后的讨论贴里学到的Solution #6 overview
- 80% feature engineering
- 10% making local validation as fast as possible
- 5% hyper parameter tuning
- 5% ensembling
-
占80%重要性的决定因素还是特征工程,尽量加上你能想象到的所有有可能影响预测结果的所有特征,包括Group by、unique、count、cumulative_count、sort、shift(next & previous)、mean、variance之类的都可以进行尝试。
-
占10%的次要因素是建立一个本地的验证数据集,这个一方面是用来验证在添加新特征或调整某个参数后是否能增加模型的预测准确度,另一方面也是为了控制如果只用Kaggle上的LB score所带来的overfitting。大神的做法是:
Let's us look at validation. This is key. If you don't have a good validation scheme then you rely solely on LB probing, which can easily lead to overfit. I ended up settling on:
- training on day <= 8, and validating on both day 9 - hour 4, and day-9, hours 5, 9, 10, 13, 14.
- retraining on all data using 1.2 times the number of trees found by early stopping in validation
Using two validation sets was to make sure I was not overfiting to one of them. The hours were selected to match the public and private test data. I also watched the train auc in the early days, discarding features that improved validation but also increased the gap with train a lot. I stopped watching train auc in the last week to speed up things, but last time I checked I had a quite small gap.
总结为尽可能通过分析,建立一个贴近Kaggle最后评分的数据集的验证急。
- 占5%的是调节参数,这一部分十分耗时间,为了节省时间,可以在Kaggle上依照别人的参数来先进行。如果自己想提高准确度,具体做法可用Grid Search:
通常我们会通过一个叫做 Grid Search 的过程来确定一组最佳的参数。其实这个过程说白了就是根据给定的参数候选对所有的组合进行暴力搜索。
1 param_grid = {'n_estimators': [300, 500], 'max_features': [10, 12, 14]}
2 model = grid_search.GridSearchCV(estimator=rfr, param_grid=param_grid, n_jobs=1, cv=10, verbose=20, scoring=RMSE)
3 model.fit(X_train, y_train)
顺带一提,Random Forest 一般在 max_features 设为 Feature 数量的平方根附近得到最佳结果。
鉴于我们一般是使用xgboost和Light GBM来训练模型,所以可以参考xgboost/Light GBM parameters
- 最后的是Ensemble
常见的 Ensemble 方法有这么几种:
- Bagging:使用训练数据的不同随机子集来训练每个 Base Model,最后进行每个 Base Model 权重相同的 Vote。也即 Random Forest 的原理。
- Boosting:迭代地训练 Base Model,每次根据上一个迭代中预测错误的情况修改训练样本的权重。也即 Gradient Boosting 的原理。比 Bagging 效果好,但更容易 Overfit。
- Blending:用不相交的数据训练不同的 Base Model,将它们的输出取(加权)平均。实现简单,但对训练数据利用少了。
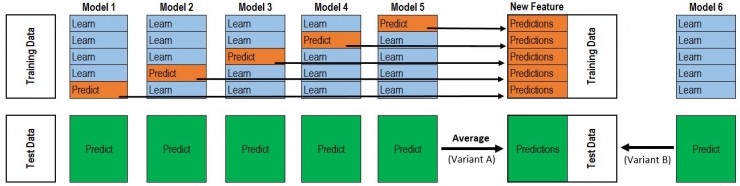
- Stacking:整个过程很像 Cross Validation。首先将训练数据分为 5 份,接下来一共 5 个迭代,每次迭代时,将 4 份数据作为 Training Set 对每个 Base Model 进行训练,然后在剩下一份 Hold-out Set 上进行预测。同时也要将其在测试数据上的预测保存下来。这样,每个 Base Model 在每次迭代时会对训练数据的其中 1 份做出预测,对测试数据的全部做出预测。5 个迭代都完成以后我们就获得了一个 #训练数据行数 x #Base Model 数量 的矩阵,这个矩阵接下来就作为第二层的 Model 的训练数据。当第二层的 Model 训练完以后,将之前保存的 Base Model 对测试数据的预测(因为每个 Base Model 被训练了 5 次,对测试数据的全体做了 5 次预测,所以对这 5 次求一个平均值,从而得到一个形状与第二层训练数据相同的矩阵)拿出来让它进行预测,就得到最后的输出。
注意内存RAM
一个竞赛的数据集一般都很大,我们在进行特征工程的往往还要加上一些特征,这个时候就有可能超出机器本身的RAM而出现内存不足问题。我们知道训练集越大,结果往往越好,为了能尽可能处理更多的数据。要养成节约内存的好习惯,具体有一些做法:
- 在导入数据之前,最好先搞清楚各个特征的极值范围,在pandas的read_csv里dtype参数定义清楚。
| Typeclass | Dtypes |
|---|---|
numpy.floating |
float16, float32, float64, float128 |
numpy.integer |
int8, int16, int32, int64 |
numpy.unsignedinteger |
uint8, uint16, uint32, uint64 |
numpy.object_ |
object_ |
numpy.bool_ |
bool_ |
numpy.character |
string_, unicode_ |
- 在确定一个数据不用后,不要忘记把它删除掉
1
2
3
4
5
6import gc
# after df is no longer in use
del df
gc.collect()
- xgboost大概要比Light GBM多需要8倍的内存
- 考虑用SWAP做虚拟内存,待补充...
- 如果还是不行,就直接在GCP上建虚拟机Running Jupyter Notebook on Google Cloud for a Kaggle challenge